This post contains my notes and scratch materials while I’m working on the song publishing process. It has to be public because I need to see the final public URI as part of the work. Keeping notes like this puts me in a position to write a program which automates the whole thing. It is vital that you only read the rest if you are an obsessive-compulsive open media software developer.
Licensing Steps
First, I’m need a stable URI for a blog entry before I publish it, which I need for Creative Commons metadata in a song file. I did that by setting the “post slug” in the WordPress blog entry editor. A final public URI can be gotten by appending that slug (e.g. “testingfixeduri”) to the blog URI root (e.g. “http://blog.gonze.com”). The final result in this case is http://blog.gonze.com/testingfixeduri.
Second, I need to set up the song file metadata in Audacity before I export to MP3 and Ogg. I plug in the above post URI to the fields WOAF and CONTACT, and plug in the URI of the license I am using (http://creativecommons.org/licenses/by-sa/3.0/) in the fields WCOP and LICENSE. Here’s what the metadata editor looked like when things were all ready:
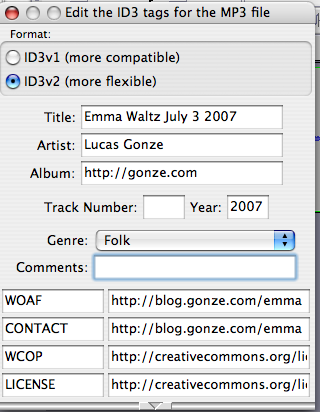
It’s not clear to me that all of those tags made sense in context, though, since some were for MP3 and some were for Ogg, and there was no way to distinguish MP3 and Ogg tags in the editor.
Third, I export from Audacity to MP3 and Ogg.
Fourth, I need content-derived identifiers to publish as “verification metadata.” The way I do that from the shell on my iBook is like this:
lucas-gonzes-ibook-g4:~/Music/release/emmawaltz-06jun2007 lucas$ md5sum *
05387f19c7e084d324a92f8a7031a35d EllaWaltz_06032007_final.ogg
6426f327e71665272c263cd42607b210 lucasgonze_EllaWaltz_06032007.mp3
According to the instructions on the Creative Commons wiki, I turn that into HTML by using this template code:
<span about="urn:sha1:MSMBC5VEUDLTC26UT5W7GZBAKZHCY2MD">
Example_Song.mp3 is licensed under
<a rel="license" href="http://creativecommons.org/licenses/by/3.0/">CC BY 3.0</a>
</span>
Given that I’m using the MD5 hash algorithm instead of SHA1, and that my own songs have their own hashes and licenses, I believe this is what I end up with:
<span about="urn:md5:6426f327e71665272c263cd42607b210">
lucasgonze_EllaWaltz_06032007.mp3 is licensed under
<a rel="license" href="http://creativecommons.org/licenses/by-sa/3.0/">CC BY 3.0</a>
</span>
<span about="urn:md5:05387f19c7e084d324a92f8a7031a35d">
EllaWaltz_06032007_final.ogg is licensed under
<a rel="license" href="http://creativecommons.org/licenses/by-sa/3.0/">CC BY 3.0</a>
</span>
On a practical level, though, this is gibberish, because I made up the md5 URN type and because I know of no consumers for this verification metadata. I am pretty sure that search engines and other bots will interpret this to mean that the embedding web page is under a Creative Commons Sharealike license, which is true only by accident and not relevant to the license on my song files. And that’s in the best case situation where I managed to correctly interpret the instructions from Creative Commons.
Note to crypto-weenies: I used MD5 instead of SHA1 because I happen to have a program to compute md5 hashes on this computer and I don’t happen to have a program to compute sha1 hashes. Please don’t carp at me — MD5 is secure enough for this application.
The last thing I need to be done with copyright is a textual explanation for the benefit of human readers, which is probably the only aspect of this rigamarole that will ever be used in practice. This is it:
These recordings are released under the terms of the <a href=”http://creativecommons.org/licenses/by-sa/3.0/”>Creative Commons Attribution-ShareAlike 3.0</a> license per <a href=”http://blog.gonze.com/2007/04/11/license-on-my-own-music/”>my boilerplate licensing statement</a>.
All together, this licensing jazz is a royal pain in the ass and most of it is not productive.
Gather media files
I make a new directory to hold all the files. This feels similar to packaging up open source software.
In Audacity I export to MP3 and Ogg Vorbis. I don’t export to a lossless format like Ogg FLAC in order to preserve the ability to sell lossless files for commercial uses.
I grab an image file of the sheet music.
I take a picture in the mirror to use as album art, then connect my camera to my laptop, import the picture into iPhoto, and export from iPhoto as PNG.
I grab a copy of the original sheet music from the Library of Congress web site. (I have previously checked the LOC copyright claims to confirm that this is OK).
Lastly, I upload these files and save the final public URL for each.
Create blog entry HTML
This is what I’ll need in the HTML:
1. Composition metadata:
1. Song title
2. Song composer
3. Publication date
2. Links to all media files
3. Link to source web site for composition
4. Media player to render the song in-place
5. Annotation about the music or recording
6. Inline image for sheet music, linked to source web site
Here’s a template to fill in with all that, using square brackets ‘[‘ and ‘]’ to mark where I need to fill in items:
<h1>[song title] [recording date]</h1> <p>This post is a recording of the composition <q><a href="[Link to source web site for composition]">[song title]</a></q> by [song composer], which was published [publication date].</p>
<p>[Annotation about the music or recording]</p>
<p><a href="[Link to source web site for composition]"><img src="[Inline image for sheet music]" alt="[Link to source web site for composition]" /></a></p>
<div>
<p>MP3: <a href="[]" title="[song title]" ><img src="[album art]" alt="" />Lucas Gonze -- [song title]</a></p>
<p>Ogg Vorbis: <a href="[]" title="[song title]" >Lucas Gonze -- [song title]</a></p>
<p>[Media player to render the song in-place]</p>
</div>
Update July 11:
Here is PHP code for filling out the template HTML.
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<?php
$songtitle = "Ella Waltz";
$recordingdate = "July 3, 2007";
$linktosourcewebsiteforcomposition = "http://memory.loc.gov/cgi-bin/ampage?collId=mussm&fileName=sm2/sm1854/732000/732150/mussm732150.db&recNum=3&itemLink=D?mussm:2:./temp/~ammem_7r3O::&linkText=0";
$songcomposer = "D.E. Jannon";
$publicationdate = "in 1854";
$inlineimageforsheetmusic = "http://gonze.com/blog/wp-content/uploads/2007/07/emmawaltz.gif";
$linktoogg = "http://gonze.com/blog/wp-content/uploads/2007/07/ellawaltz_06032007_final1.ogg";
$linktomp3 = "http://gonze.com/blog/wp-content/uploads/2007/07/lucasgonze_ellawaltz_06032007.mp3";
$inlineimageforsheetmusic = "http://gonze.com/blog/wp-content/uploads/2007/07/emmawaltz.gif";
$albumart = "http://gonze.com/blog/wp-content/uploads/2007/07/lucasgonze_ellawaltz_06032007.jpg";
$annotationaboutthemusicorrecording =<<<END
<p>It is the third of a set of three waltzes by D.E. Jannon, though I don't consider the series finished because I want to redo the first one.</p>
<p>When I play this I imagine that the 3 waltzes are named after the composer's daughters. In my imagination I think of this third one as being for the youngest, who is going through a phase where she falls down a lot, drops things, and otherwise has a lot of accidents. I usually make up little stories along these lines about songs.</p>
<p>By the way, I got the name slightly wrong while I was working, and even though I corrected it in the end some of the metadata and file names are wrong. The wrong name is "Emma Waltz." The right name is "Ella Waltz."</p>
END;
print <<<END
<h1>${songtitle} ${recordingdate}</h1>
<p>This post is a recording of the composition <q><a href="${linktosourcewebsiteforcomposition}">${songtitle}</a></q> by ${songcomposer}, which was published ${publicationdate}.</p>
<div>
<p></p>
<p>MP3: <a href="${linktomp3}" title="${songtitle}" ><img src="$albumart" alt="" width="200" />Lucas Gonze -- ${songtitle}</a></p>
<p>Ogg Vorbis: <a href="$linktoogg" titl!e="${songtitle}" >Lucas Gonze -- ${songtitle}</a></p>
</div>
<p>${annotationaboutthemusicorrecording}</p>
<p><a href="${linktosourcewebsiteforcomposition}"><img src="${inlineimageforsheetmusic}" alt="${linktosourcewebsiteforcomposition}" /></a></p>
<p>These recordings are released under the terms of the <a href="http://creativecommons.org/licenses/by-sa/3.0/">Creative Commons Attribution-ShareAlike 3.0</a> license per <a href="http://blog.gonze.com/2007/04/11/license-on-my-own-music/">my boilerplate licensing statement</a>.</p>
END;
?>
